이전글에서 간단하게 Spring Batch가 수행되게 구현해보았습니다.
JobRepositoy
db또는 메모리에 스프링배치가 실행할 수 있도록 배치 메타데이터로 관리하는 클래스입니다.
메타데이터는 나중에 더 자세히 알아보겠습니다. 여기에 이어지는 글입니다.
메타 데이터란, 데이터를 설명하는 데이터라고 보시면 됩니다.
위키피디아보다 나무위키가 더 설명이 잘되어있어 나무위키 링크를 첨부합니다
Spring Batch의 메타 데이터는 다음과 같은 내용들을 담고 있습니다.
- 이전에 실행한 Job이 어떤 것들이 있는지
- 최근 실패한 Batch Parameter가 어떤것들이 있고, 성공한 Job은 어떤것들이 있는지
- 다시 실행한다면 어디서 부터 시작하면 될지
- 어떤 Job에 어떤 Step들이 있었고, Step들 중 성공한 Step과 실패한 Step들은 어떤것들이 있는지
등등 Batch 어플리케이션을 운영하기 위한 메타데이터가 여러 테이블에 나눠져 있습니다.
메타 테이블 구조는 아래와 같습니다.
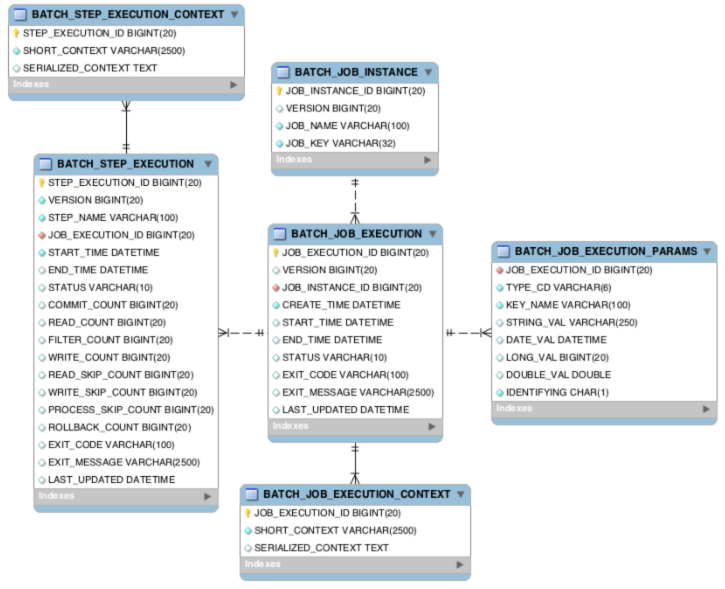
사진 출처: 스프링배치 문서
위와 같은 테이블들을 메타 테이블이라고 합니다. 메타테이블에대해 알아 보겠습니다.
- 배치 실행을 위한 메타 데이터가 저장되는 테이블
- BATCH_JOB_INSTANCE
- Job이 실행되며 생성되는 최상위 계층의 테이블
- job_name과 job_key를 기준으로 하나의 row가 생성되며, 같은 job_name과 job_key가 저장될 수 없다.
- job_key는 BATCH_JOB_EXECUTION_PARAMS에 저장되는 Parameter를 나열해 암호화해 저장한다.
- BATCH_JOB_EXECUTION
- Job이 실행되는 동안 시작/종료 시간, job 상태 등을 관리
- BATCH_JOB_EXECUTION_PARAMS
- Job을 실행하기 위해 주입된 parameter 정보 저장
- BATCH_JOB_EXECUTION_CONTEXT
- Job이 실행되며 공유해야할 데이터를 직렬화해 저장
- BATCH_STEP_EXECUTION
- Step이 실행되는 동안 필요한 데이터 또는 실행된 결과 저장
- BATCH_STEP_EXECUTION_CONTEXT
- Step이 실행되며 공유해야할 데이터를 직렬화해 저장
이 메타데이터의 스크립트는 spring-batch-core/org.springframework/batch/core/* 하위에 위치하고 있습니다.
- 스프링 배치를 실행하고 관리하기 위한 테이블
- schema.sql 설정
- schema-**.sql의 실행 구분은
- spring.batch.initialize-schema config로 구분한다.
- ALWAYS, EMBEDDED, NEVER로 구분한다.
- ALWAYS : 항상 실행
- EMBEDDED : 내장 DB일 때만 실행
- NEVER : 항상 실행 안함
- 기본 값은 EMBEDDED다.
저는 mysql을 사용하기 때문에 schema-mysql.sql을 열어준뒤에 테이블을 생성해주도록 하겠습니다.
schema-mysql.sql
-- auto-generated definition
-- No source text available
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
이런식으로 테이블이 생성이 잘 되었습니다. 그리고 application.yml에서 스크립트 생성 시점을 설정할 수 있습니다.
application.yml
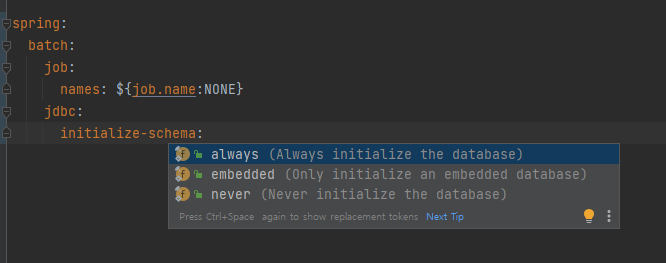
개발 환경에서는 always 나 embeded를 하지만 운영 환경에서는 never로 설정해두는것을 권장한다고 합니다.
운영환경에서 스프링 배치에 의해서 스크립트가 자동으로 생성된다는 의미는 sql의 ddl이 운영데이터베이스에 직접 실행된다는 의미 입니다. 그래서 위험합니다.
이제 각 테이블들의 역할을 알아보겠습니다.
- JobInstance : BATCH_JOB_INSTANCE 테이블과 매핑
- JobExecution : BATCH_JOB_EXECUTION 테이블과 매핑
- JobParameters : BATCH_JOB_EXECUTION_PARAMS 테이블과 매핑
- ExecutionContext : BATCH_JOB_EXECUTION_CONTEXT 테이블과 매핑
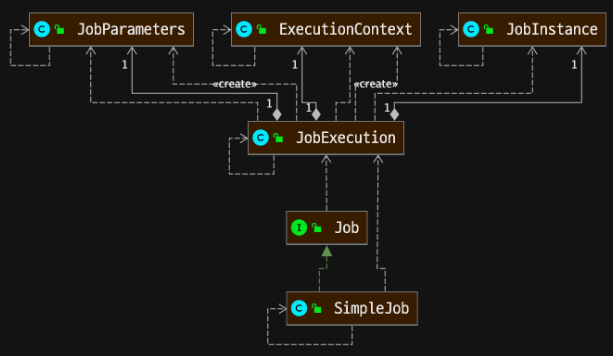
JobInstance의 생성기준은 JobName과 Jobkey와 입니다.
- JobInstance의 생성 기준은 JobParamters 중복 여부에 따라 생성된다.
- 다른 parameter로 Job이 실행되면, JobInstance가 생성된다.
- 같은 parameter로 Job이 실행되면, 이미 생성된 JobInstance가 실행된다.
- JobExecution은 항상 새롭게 생성된다.
- 예를 들어
- 음 Job 실행 시 date parameter가 1월1일로 실행 됐다면, 1번 JobInstance가 생성된다.
- 다음 Job 실행 시 date parameter가 1월2일로 실행 됐다면, 2번 JobInstance가 생성된다.
- 다음 Job 실행 시 date parameter가 1월2일로 실행 됐다면, 2번 JobInstance가 재 실행된다.
- 이때 Job이 재실행 대상이 아닌 경우 에러가 발생한다.
- Parameter가 없는 Job을 항상 새로운 JobInstance가 실행되도록 RunIdIncrementer가 제공된다.
근데 저번 글에서 만든 Job은 재실행대상이라고 지정하지 않았는데 어떻게 에러가 나지 않고 새로운 Job을 실행했을까요.
@Bean
public Job helloJob() {
return jobBuilderFactory.get("helloJob")
.incrementer(new RunIdIncrementer())
.start(this.helloStep())
.build();
}
new RunIdIncrementer() 클래스는 새로운 잡 인스턴스를 시퀀스방법으로 만들도록 해줍니다. RunId라는 파라미터값을 내부에서 자동으로 생성해서 이 클래스없이 실행되면 매번 동일한 잡으로 실행된다는 의미입니다.
이 설정을 추가하면 항상 다른 잡인스턴스를 실행된다고 생각해야합니다.
hellojob을 실행하면 새로운 RunId가 BATCH_JOB_EXECUTION_PARAMS 테이블에 인서트 되는지 확인해 보겠습니다.
appication-mysql.yml
spring:
datasource:
hikari:
jdbc-url: jdbc:mysql://127.0.0.1:3307/spring_batch?characterEncoding=UTF-8&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: jisu
password: 1234
batch:
initialize-schema: never
제 컴퓨터는 mariaDB가 3306 포트를 사용중이여서 mysql은 3307포트를 사용중입니다. initialize-schema 은 never로 설정 해줍니다.
그리고 오른쪽 상단에 Edit configurations을 눌러줍니다.
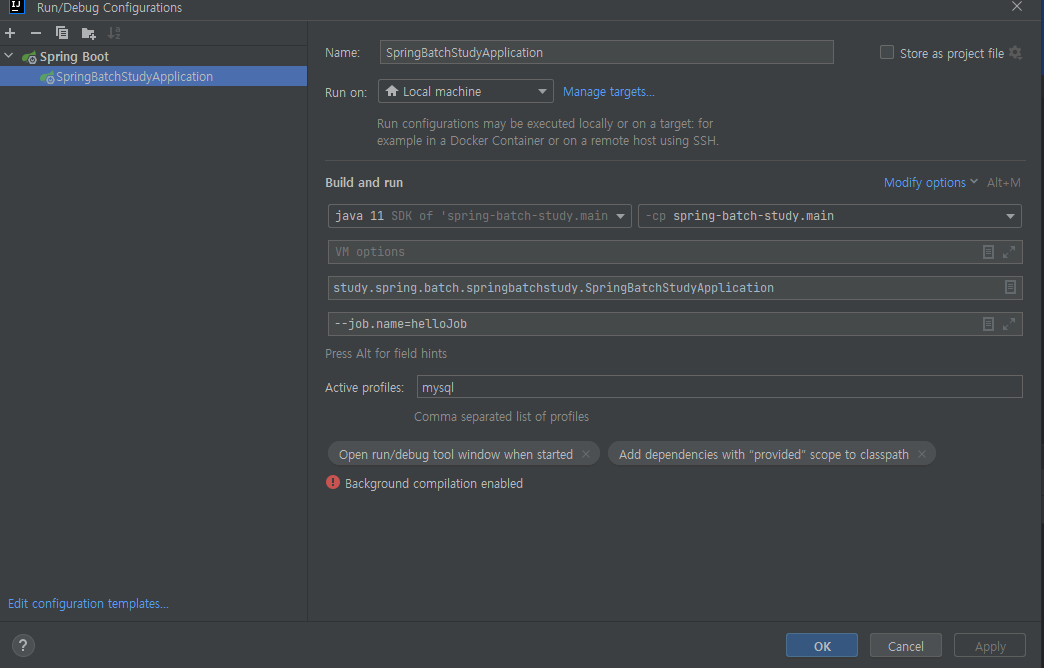
Active profies 에 mysql을 적어 줍니다. 이렇게 되면 스프링부트는 application의 mysql.yml 파일(application-mysql.yml)을 자동으로 읽어서 프로젝트를 시작하게 됩니다.
프로젝트를 실행해보겠습니다.
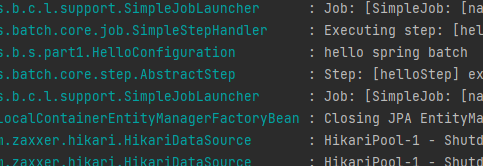
hello spring batch 가 잘 나오고 프로젝트가 잘 실행되었습니다.
그리고 다시 한번 실행을 시켜보겠습니다.
select *
from batch_job_execution_params;그리고 위와 같이 테이블을 조회해봅시다.

두번 실행 했으므로 key_name의 run_id가 두번 생성되었고 LONG_VAL이 1,2 로 서로 다른 값으로 인서트 된것을 확인할 수 있습니다.
정리
잡 인스턴스의 생성기준 : 잡 이름과 잡파라미터의 값을 기준으로 잡인스턴스가 실행되느냐 재실행되느냐, 재실행의 실패하느냐 결정이 됩니다. 하나의 잡은 항상 같은 파라미터로 실행될수 없습니다.
ExcutionContext는 잡과 스텝의 컨텍스트를 관리하는 객체입니다. 이 객체를 통하여 데이터를 서로 공유 할 수있습니다.
'Spring Boot > Batch' 카테고리의 다른 글
| [Batch] ItemWriter 데이터 쓰기 (0) | 2022.08.08 |
|---|---|
| [Batch] ItemReader (JDBC,JPA) (0) | 2022.08.08 |
| [Batch] Execution 데이터 공유 (0) | 2022.07.28 |
| [Batch] 스프링 배치 시작하기 (0) | 2022.07.28 |

댓글